

The current generation of Large Language Models (LLMs) has revolutionized artificial intelligence, ushering in an era of unprecedented utility. Yet, for all their power, these systems suffer from a critical, fundamental flaw: poor long-term memory and reasoning over knowledge. This limitation stunts their evolution into fully autonomous, reliable agentic systems. At RUNSTACK, we recognized that pushing the boundaries of AI required transcending the mathematical constraints of current designs. Our answer is HyperMemory, a universal mathematical structure designed to serve as the flexible, logical, and scalable memory architecture that complex AI agents demand.
The Current State of Long Term Memory
The struggle of contemporary LLMs with memory is deeply rooted in their underlying structure. Being recurrent in nature, they operate within a defined boundary: the context window. This context window represents the entirety of the "new stuff" an LLM can learn or process in a given moment. Anything outside this window is effectively forgotten unless retrieved or re-input. This recurrent limitation is precisely what makes achieving true long-term learning and sustained, complex reasoning a near-impossible task for LLMs in their native form.
The industry's first attempt to patch this memory deficit was through Retrieval-Augmented Generation (RAG). While RAG systems marked an important step, they introduced their own set of significant problems. Traditional RAG relies heavily on vector search and semantic similarity. The retrieval process essentially asks, "What concepts are similar to this query?". However, this method is only weakly analogous to how the human mind uses attention. Human attention allows the mind to navigate and logically connect disparate pieces of information, a process far more intricate than simple similarity matching.
Attempts to manage complex knowledge bases, such as in the development of a Personal Assistant Agent, illuminated these RAG system shortcomings. With hundreds of pages of documents, history, and emails inserted into the knowledge base, a vector-based RAG system struggled profoundly when asked to perform logic over the knowledge base. The semantic-only search was insufficient for complex tasks like rule-following (following a process, for example) or mathematical reasoning, areas where vanilla LLMs already face inherent weaknesses. At the time, even without sophisticated tool-using agents, the core issue remained: there was no underlying data structure capable of supporting the agent's need for reasoning, math, and complex knowledge retrieval beyond mere contextual similarity. The memory itself needed to be a tool that facilitated these weaknesses. The necessity was clear: a structure was needed that could bolster the LLMs' native capabilities for logical inference and structured computation.
“There was no underlying data structure capable of supporting the agent's need for reasoning, math, and complex knowledge retrieval beyond mere contextual similarity.”
Hypergraphs: The End-All Be-All of Mathematical Structure
The fundamental breakthrough achieved by RUNSTACK lies in adopting the hypergraph as the foundational mathematical structure for long-term memory. In the hierarchy of mathematical objects, from scalars and linear spaces to trees and graphs, the hypergraph stands as the most generalized and powerful, essentially the "end all be all". All concepts learned by neural networks, entire processes, and full memories can be represented as hypergraphs. This universality is crucial because it provides the flexibility needed for agents to manage arbitrary, complex, and evolving knowledge systems.
A hypergraph generalizes the concept of a traditional graph, where a single edge can only connect two nodes. In a hypergraph, an edge can connect any number of nodes—these are known as hyper edges. While the system can hold regular edges (connecting two nodes), it fully supports hyper edges, enabling the representation of relationships that involve three or more entities simultaneously. This multi-entity relationship mapping is vital for capturing the intricate, real-world dependencies found in large systems and complex knowledge domains.

The structure is not a mere symbolic construct; it is engineered for agentic consumption. While it functions similarly to a labeled property graph, possessing metadata on both its directional and nondirectional edges and nodes, the implementation at RUNSTACK is tailored for LLM interaction. All structured data within the graph is stored in JSON format, a language the LLM can read and process with high effectiveness. Crucially, the LLM uses natural language and attention to navigate the hypergraph, moving beyond the deterministic traversal methods of traditional graph databases. The agent employs its inherent attention mechanisms to follow pathways and draw connections, making the navigation process more organic and context-sensitive than statistical data-driven searches.
This design prioritizes memory standardization and atomic swapping. The HyperMemory is saved as a collection of JSON files, ensuring the memory structure is atomic and standardized. This standardization allows for the seamless swapping of memories between agents. An agent's knowledge, whether it be a detailed sales script, a complex code architecture, or an entire ecosystem ontology, can be contained in a portable file and instantly loaded by any other agent, facilitating rapid knowledge transfer and deployment.
Agentic Autonomy
One of the most profound elements of the HyperMemory architecture is its inherent arbitrary nature. While the HyperMemory technology is universal, the meaning of the specific nodes and edges is not predefined. If not explicitly instructed, the agent itself can determine what the HyperMemory represents. This level of contextual flexibility is why the HyperMemory is perfectly suited as a memory system for agents. It is a structure that is shaped by the agent's current task and understanding.
This flexibility is underpinned by the agent's core intelligence. Instead of spending vast amounts of time and effort building a rigid, human-defined ontology, a task that can consume over 90% of the work in traditional graph methods, the agent relies on the LLM’s embedded first-order logic and training. This inherent common ground allows the agent the freedom to operate based on context and significantly reduces the need for fundamental structural work. The LLM applies an inherent, predefined methodology when creating these HyperMemories, ensuring a baseline level of structure. Furthermore, the LLM’s context-based inertia means that its prior work (such as building a HyperMemory of the Quality Assurance process) influences and formats subsequent memory creations.
The HyperMemory architecture introduces a tiered approach to agent interaction, separating the agents that manage memory from the agents that use it. A HyperMemory Agent possesses a meta-understanding; it knows its memory is a hypergraph and its job is to manage, construct, and update this structure at an arbitrary, high level. In contrast, a Sales Agent may have a HyperMemory loaded into its memory, but its internal prompt doesn't inform it of this structure. It simply uses tools like "recall" to access the memory, which is then interpreted by the LLM as structured guidance. This separation of concerns allows for the creation of specialized agents and prevents performance bottlenecks.
Advanced Memory Operations and Dynamic Collaboration
The utility of HyperMemory extends beyond simple storage and retrieval through advanced features that enable true agent collaboration and dynamic knowledge manipulation.
Subgraphs and Permission Schemas
When an agent performs a memory recall, the system returns a subgraph, a contextual slice containing all the relevant nodes and edges down to a specified depth. Because this subgraph is returned via a tool call, it can be sent directly to other agents for collaboration. This process is essential for tasks requiring a synthesis of knowledge from multiple sources or roles.
Furthermore, because the HyperMemories are stored as files, they naturally integrate with permission schemas. This enables memory to be separated into distinct spaces based on access rights and mutability.
Read-Only Memory: Used for immutable data, such as core business logic, sales scripts, or system procedures. A designated agent may have write access to create or update this core knowledge, but all operational agents access it as read-only, ensuring consistency and adherence to established rules.
Read and Write Memory: Used for live data, such as conversation records or active session history. An agent, like a sales agent, can have write access to this space to record, edit, and update its immediate learning and observations, ensuring its memory evolves over time. This distinction allows for a functional memory (active data) and a referential memory (core knowledge) to coexist and be fused during logical inference.
HyperMemory in Action
HyperMemory is not a theoretical construct; it is a proven architecture that has demonstrated its power in complex, real-world applications within the RUNSTACK ecosystem.
Structuring the RunStack Codebase
For projects with significant complexity, such as the large RUNSTACK codebase, a flat document search results in a deluge of confusing noise. An agent tasked with navigating this codebase needs structure. The HyperMemory was deployed to organize the system components across different hierarchical layers and levels. An agent can look at the highest layer, identifying the back-end versus the front-end, and then drill down to lower layers showing components like the Fast API stack or specific communication protocols. By representing the codebase as a HyperMemory, the agent is no longer forced to perform resource-intensive discovery through source code access. Instead, it consults its HyperMemory, which provides the direct path to component locations, file paths, and associated knowledge that has been learned along the way. This capability allows the agent to fit a massive amount of project learning into a small context window, enabling quick, precise, and contextualized actions. This structured approach transformed the coding agent, allowing it to move past mere search and immediately access the knowledge necessary for complex tasks.
The Autonomous Sales Agent Success Story
Perhaps the most compelling demonstration of HyperMemory’s power comes from its successful deployment in an autonomous sales agent. The initial goal was to create an agent that could follow a specific process, such as a sales script, precisely and effectively. The HyperMemory Agent was instructed to create a generic sales call HyperMemory. This HyperMemory was not a flat script; it was an action-based system. The agent followed the procedural structure exactly, demonstrating an ability to identify its current location within the call (e.g., trust-building phase, objection handling) by consulting its memory.
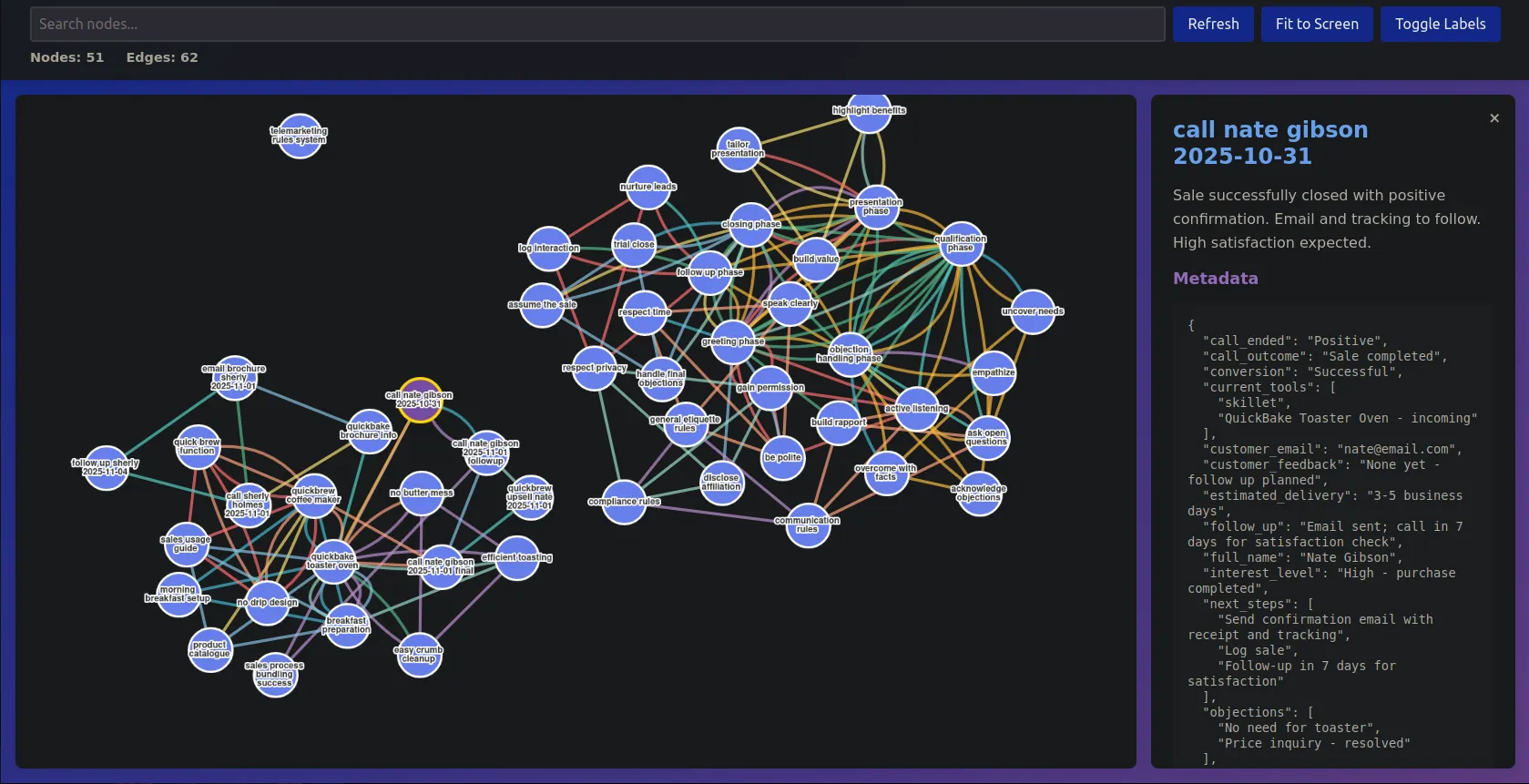
In one live demonstration, the agent successfully sold a toaster and, in a subsequent conversation, cross-sold a coffee machine. This success was due to the agent's sophisticated use of the HyperMemory in several ways:
Structured Data Integration: The agent used structured data within the graph to record and utilize user preferences and pain points effectively.

Logical Inference: The agent was able to create a separate HyperMemory attached to the specific chat session. It then performed logical inference by fusing the conversation memory (the live data) with its existing sales knowledge (the read-only procedural memory). This fusion allowed it to dynamically generate contextual rebuttals and adapt its strategy based on learned information.
Evolutionary Memory: Over time and across different conversations, the agent demonstrated its ability to edit and update its memory effectively, incorporating new learning. For instance, when later engaging with the agent as a different person, it pulled up memories from a previous conversation to use past rebuttals, proving the memory system was not static but was continuously evolving and improving its effectiveness.
The Foundation for Next-Generation Agents
The transition from merely intelligent models to truly autonomous, agentic systems requires a radical rethinking of memory architecture. RUNSTACK’s HyperMemory represents an essential piece. By moving beyond the limitations of recurrent architectures and semantic-only RAG, HyperMemory provides the mathematical structure necessary to support the logical inference, complex reasoning, and structured knowledge management that current LLMs lack.
By treating memory as an arbitrary, flexible, and powerful tool that can be partitioned, secured with permissions, and dynamically manipulated through processes like unfolding and serialization, RUNSTACK has created the foundation for AI agent memory capable of sustained, complex, and collaborative work. HyperMemory is not just storage; it is the cognitive scaffolding that transforms an LLM into a reliable, learning, and architecturally sound agent now and as they evolve and become more sophisticated. The success observed in managing the complexity of the RUNSTACK codebase and the autonomy demonstrated by the sales agent confirms that HyperMemory is the vital, long-sought piece of the puzzle that will enable AI to reach its full potential.







